
The Engineer Who Brought Deep Learning to Millions Says AI Is on the Wrong Track
🟡 Welcome back to this new edition of dotAI radar, your shortcut to what matters in AI engineering.


One of deep learning’s leading voices thinks the field is on the wrong track.
And he would know, he built the library that put neural networks in the hands of millions.
👋 Welcome back to dotAI radar, the AI newsletter that tracks how AI is really being built and used.
This issue’s Portrait of the Month profiles François Chollet, the engineer behind Keras, who argues that scaling up models won’t deliver true intelligence (or AGI).
In his view, today’s LLMs are basically just giant memorization engines. After nearly a decade at Google, he is now pursuing a different path to AI, one focused on reasoning and adaptability instead of brute-force scale.
His story shows why progress in AI may hinge more on learning strategies than on raw size.
🔥 Hot on the Radar
Fresh tools, research, and lessons shaping how AI is built and applied. 👇
⚡ Offloading without the slowdown: DeepSpeed releases ZenFlow
Microsoft’s DeepSpeed team has open-sourced ZenFlow, a new extension designed to eliminate GPU idle time when training large language models.
Offloading training to CPUs often slows things down dramatically. For example, pushing Llama 2-7B to CPU memory on 4× A100 GPUs stretched each step from 0.5s to over 7s (a 14× slowdown).
ZenFlow avoids this by decoupling GPU and CPU work with an “importance-aware” pipeline that overlaps CPU calculations and PCIe transfers with GPU compute, so accelerators stay busy.
Early results show 85% fewer GPU stalls and up to 5× faster fine-tuning versus ZeRO-Offload, without sacrificing accuracy. In short, teams can train bigger-than-memory models without the usual offload penalty.
The key takeaway: By eliminating offload-induced stalls, ZenFlow lets anyone fine-tune large models beyond GPU memory limits at near full speed.
This makes LLM training more accessible: even setups with modest GPU memory can handle larger models without the usual slowdowns, bringing advanced AI within reach for more teams.
🤖 Coding tasks on autopilot: GitHub adds Copilot Agents panel
GitHub has launched a new “Agents” panel that lets developers trigger the Copilot coding agent from anywhere on the platform.
Previously, Copilot’s AI agent could only be triggered via GitHub Issues (assigning it an issue to code and waiting for a pull request). Now, with the Agents panel, a lightweight overlay available on every page, you can hand off a task to Copilot with a quick natural-language prompt and watch its progress in real time.
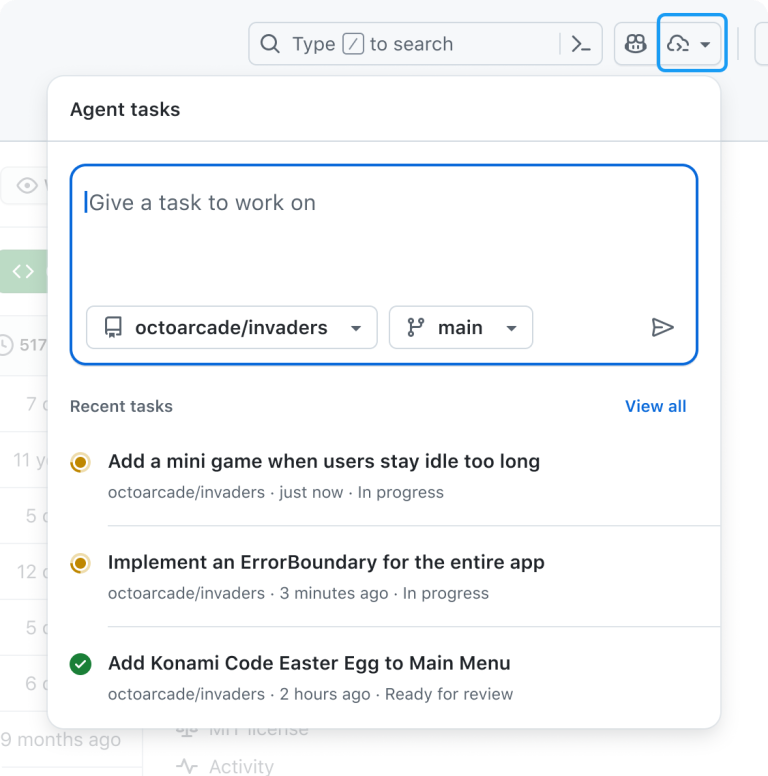
From the panel you can:
Delegate tasks to Copilot without leaving your current page
Monitor progress with live status updates
Review the draft pull requests it creates
Multiple tasks can run in parallel. The aim is to integrate AI assistance directly into workflows, with Copilot handling routine coding in the background and returning ready-to-review pull requests.
What it means for developers: GitHub’s expanding Copilot from an autocomplete tool into a more autonomous coding assistant, freeing developers to focus on higher-value work.
🔓 Open weights from xAI: Grok 2.5 lands on Hugging Face
xAI has released Grok model weights on Hugging Face.
The model card lists “Grok 2” with 42 weight files (about 500 GB) and SGLang serving instructions. The reference setup runs across eight GPUs with at least 40 GB of memory each.
Elon Musk said the Grok 2.5 model (xAI’s best model from last year) is now open source and that Grok 3 will follow “in about six months.”
The weights ship under the Grok 2 Community License. Research use is allowed, commercial use is permitted only under xAI’s acceptable use policy, and you may not use the materials or outputs to train, create, or improve other foundation or LLM models (beyond fine-tuning Grok 2). Redistribution requires “Powered by xAI” attribution.
Why this is interesting: You can now inspect, run, and fine-tune a recent xAI model with full weights, enabling independent evaluation and local testing.
xAI previously reported Grok-2 as competitive on benchmarks like MMLU, GPQA, and MATH, and with full weights available teams can test Grok 2.5 directly, fine-tune it for their own tasks, and compare its performance against other open models.
☀️ Space weather forecasting goes AI: IBM & NASA open-source Surya model
IBM Research and NASA have unveiled Surya, a new open-source foundation model trained on nine years of Solar Dynamics Observatory data to predict space weather impacts on Earth.

Surya recognizes solar activity that can disrupt GPS, power grids, and satellites, achieving 16% higher accuracy than prior methods. It doesn’t just flag flares but also generates high-resolution forecasts of where they’ll occur, up to 2 hours in advance, making it the first reported AI model to generate visual flare forecasts.
By open-sourcing Surya on Hugging Face, IBM and NASA give researchers a new tool to improve space-weather forecasting and safeguard critical systems.
Why it matters: Major solar outbursts can knock out communication, navigation, and power systems, yet forecasting these events has been notoriously difficult.
By releasing Surya openly, IBM and NASA provide the space-weather community with a model to boost forecasting accuracy and safeguard satellites and power grids.
📚 AI-native publishing: aiXiv proposes an agentic preprint platform
A new preprint outlines aiXiv, an open-access platform designed for both human and AI “scientists.”
The system’s multi-agent workflow lets submissions be proposed, reviewed, and iteratively revised by human and AI agents together, with API and Model Context Protocol (MCP) interfaces for integration into existing toolchains.
The authors report experiments where iterative revise-and-review on aiXiv improved the quality of AI-generated proposals and papers.
The public GitHub repository includes a frontend, API skeleton, setup instructions, and documentation placeholders, allowing you to explore the architecture or integrate agents via REST ahead of any hosted service being available.
Worth noting: aiXiv is still a research prototype, not an operational service.
It aims to address gaps in today’s publication ecosystem, but questions of provenance, moderation, and evaluation remain open. For now, its MCP/API hooks make it a practical reference for experimenting with agentic pipelines.
Portrait of the Month: François Chollet
He built the deep-learning API behind recommendations at YouTube, Netflix, Spotify, and others.
Then he designed a test that humans solve easily, yet models had struggled for years.
In late 2024, OpenAI’s o3 lifted scores on the ARC-AGI benchmark he introduced in 2019.
A few months ago, ARC-AGI-2 reset the bar.
His take? 👉 “LLMs are 100% memorization. There is no other mechanism at work.”
François Chollet is one of the voices arguing that scaling LLMs won’t lead to AGI.
Meet our dotAI radar Portrait of the Month. 👇

For nearly a decade, François Chollet has played a paradoxical role in AI: building the tools that democratized deep learning for millions while arguing the field is chasing the wrong target.
Across the field, his influence is hard to miss.
Nearly 3 million developers use Keras.
It powers billions of recommendations daily at YouTube, X (Twitter), TikTok and others.
He also wrote Deep Learning with Python, a go-to reference for practitioners, with over 100,000 copies sold.
In November 2024, he left Google and co-founded Ndea, an AGI research lab pursuing guided program synthesis as a path beyond next-token prediction.
How Keras happened
An engineer by training, François Chollet joined Google in 2015.
In his spare time, while exploring natural language processing, he couldn’t find tools that made building recurrent neural networks straightforward, so he started Keras out of frustration.
The idea was simple: design for humans first.
By focusing on readability and quick iteration, Keras put deep learning within reach for many.
⚡️ What began as a one-person side project grew quickly: within two years, it went from a single user to 100,000. Today it’s used by nearly 3 million developers.
As mentioned above, major companies adopted Keras, and it later became TensorFlow’s official high-level API.
The test that humbled AI
While Keras was empowering millions to build neural networks, François was also pushing a different view of intelligence.
In 2019, he introduced the Abstraction and Reasoning Corpus (ARC-AGI) with his paper On the Measure of Intelligence.
💡 The idea is straightforward: intelligence is how efficiently you acquire new skills across tasks, not how much skill you’ve accumulated.
As Jean Piaget, a Swiss developmental psychologist, put it: “Intelligence is what you use when you don’t know what to do.”
By this measure, memorizing patterns from internet-scale data isn’t intelligence.
ARC-AGI turns that idea into code: small grid puzzles that require spotting a pattern from a few examples and applying it to a new case.
The required priors are basic: shape, color, adjacency. Each puzzle is new by design, so stored knowledge doesn’t help: you have to adapt.
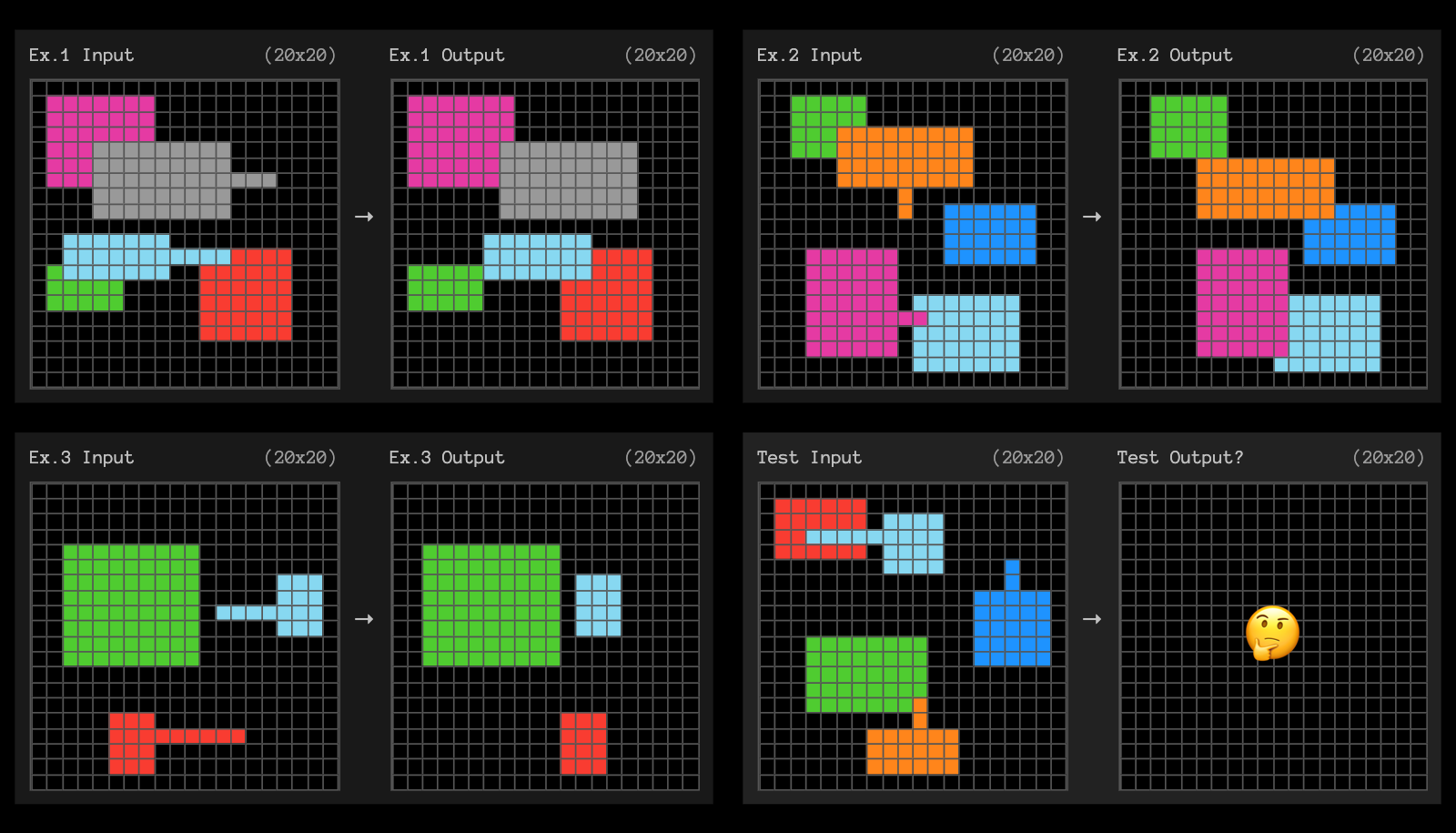
ARC-AGI is built to resist memorization: public training tasks teach the basics, but evaluation happens on held-out sets you never see during development.
For years, while most humans could solve these tasks, the best AI systems struggled to exceed 5 to 30%.
Then in December 2024, OpenAI's o3 cracked it: 87.5% on ARC-AGI, matching human performance.
François's response was nuanced: "This is a surprising and important step-function increase in AI capabilities." Yet he maintains: "Passing ARC-AGI does not equate to achieving AGI."
He also pointed out the economics:
"You could pay a human to solve ARC-AGI tasks for roughly $5 per task (we know, we did that), while consuming mere cents in energy. Meanwhile o3 requires $17-20 per task in the low-compute mode."
Then came ARC-AGI-2.
Released in March 2025, it's designed specifically to challenge the new reasoning systems like o3.

While ARC-AGI-1 tested whether AI could move beyond memorization, ARC-AGI-2 asks: can it do so efficiently?
The gap is clear: on ARC-AGI-2, pure LLMs score 0%, and OpenAI’s released o3 variants come in below 3%, while every task was solved by at least two humans within two attempts.
That’s the point of the new benchmark: it targets weak spots in today’s AI reasoning (symbolic interpretation, composing rules, applying them in context). Problems many people solve in seconds still challenge the most advanced models.
And the ARC-AGI series is still evolving. A third benchmark, ARC-AGI-3, is currently in development.
It moves from static puzzles to interactive reasoning environments, where agents must perceive, plan and act across multiple steps, closer to how humans learn in the real world.
A preview was released just last month (July 2025) with a handful of games, and the full launch is expected in 2026.
Questioning the scaling approach
By 2024, François Chollet had become one of the field’s loudest skeptics of the “bigger is better” paradigm.
He argued that scaling up data and parameters was not a path to intelligence but to ever-larger memorization engines.
In an interview, he went so far as to say that OpenAI had “set back progress to AGI by five to ten years”, both by closing down frontier research publishing and by triggering a gold rush where “LLMs have sucked the oxygen out of the room… everyone is doing LLMs.”
His critique extended to economics: in his view, the AI industry was pouring billions into models with limited returns.
Estimates he cited suggested $90 billion invested in 2023–24 generated only about $6 billion in earnings, a sign that hype was running ahead of results. For Chollet, the frenzy around LLMs was not just inefficient, it was crowding out exploration of fundamentally different architectures.
The alternative he advocates has been consistent: rather than brute-force competence through scale, he believes progress requires hybrid systems.
In his words, “Deep learning and discrete program search have very complementary strengths and limitations… the way forward is to merge the two.”
His own work backs this up. The Xception architecture, which he introduced in 2017 and has since been cited over 18,000 times, showed how smarter design can deliver major efficiency gains without just making networks bigger.
Building the alternative: Ndea
In November 2024, after nearly a decade at Google, François left to put this vision into practice.
He co-founded Ndea (pronounced like “idea” with an N) with Mike Knoop, co-founder of Zapier.

Ndea’s goal is ambitious: AI that can “learn at least as efficiently as people” and keep improving with no bottlenecks.
Its first focus is deep-learning-guided program synthesis: using neural networks to guide a search through small program-like modules until a generalizable solution emerges.
In other words, marrying intuitive pattern recognition with rigorous symbolic reasoning.
The move coincided with the growth of the ARC Prize, a benchmark competition that Chollet and Knoop co-founded in 2024 with a $1 million purse.
The prize challenges teams to build systems that can solve ARC puzzles, pushing research toward reasoning and adaptation rather than scale alone. In its first year, 1,430 teams worldwide submitted over 17,000 solutions.
The initiative has since expanded into a foundation dedicated to reasoning benchmarks, attracting not only researchers but also startups and corporate labs.
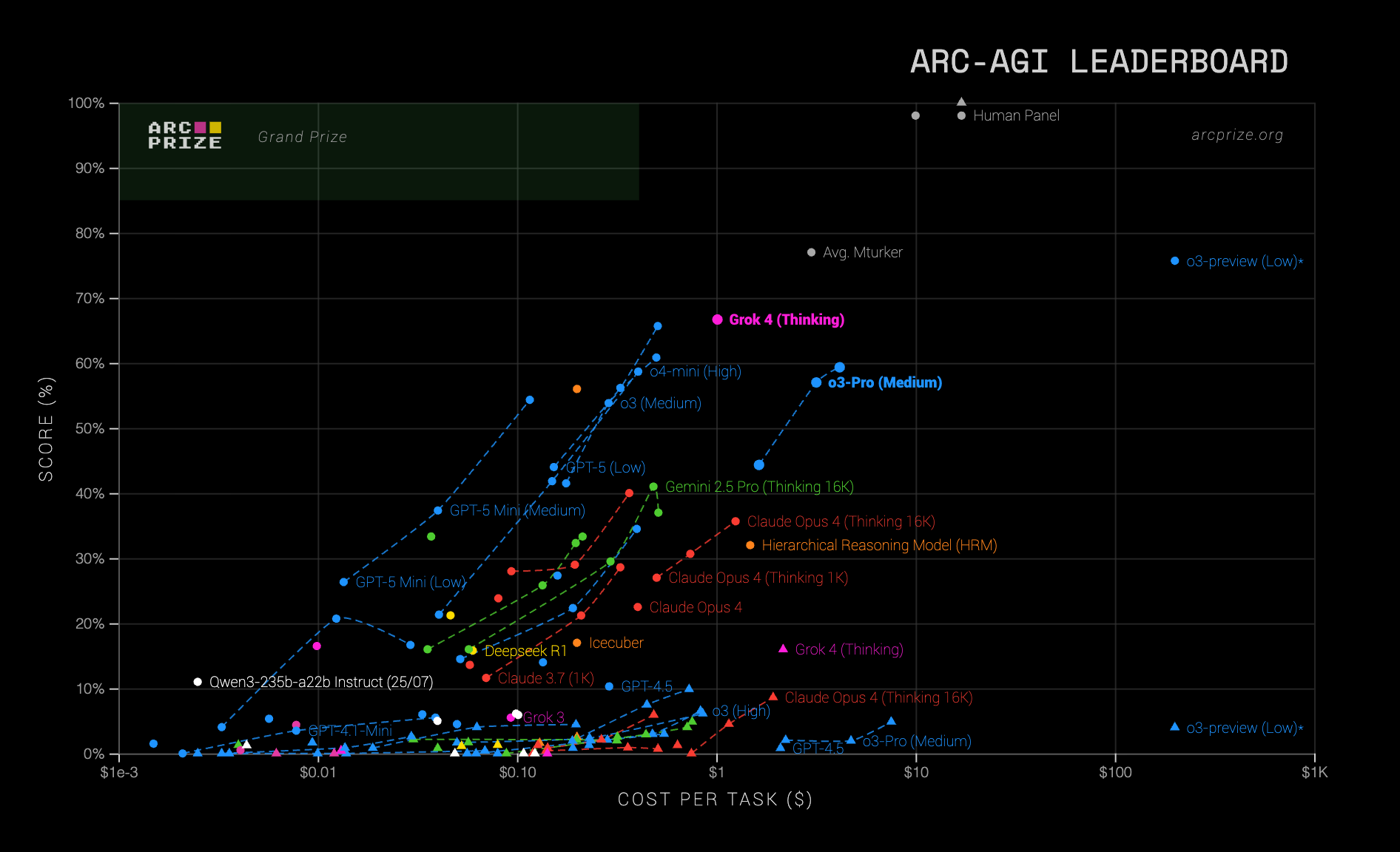
By early 2025, even OpenAI was collaborating with François Chollet’s group on ARC-AGI-2, a sign that the questions he has been raising for years now sit at the center of the frontier.
Whether Ndea will succeed is uncertain, but the effort has already reshaped the conversation.
In an era dominated by scale and compute budgets, François reminds us that AI’s future may hinge as much on how systems learn as on how large they are.
A lasting mark on AI’s direction
François Chollet’s career connects two threads that rarely meet: building tools that millions rely on, and questioning the foundations of the field itself.
Keras made deep learning accessible far beyond the research lab.
ARC reframed what it means to measure intelligence.
Ndea now pushes an alternative path toward systems that learn through adaptation rather than scale alone.
Whether this approach proves decisive remains open. But his decade-long effort has already changed how progress is tracked and debated.
Benchmarks like ARC-AGI are now unavoidable for any model claiming reasoning ability, and the conversation around AGI has shifted from size to adaptability.
In a discipline often defined by rapid cycles of hype, François’s influence lies in pushing the field to confront harder questions. From Keras to ARC to Ndea, he has kept the focus on how systems learn, not just how large they are.
🟡 dotAI is back November 6 in Paris. Don’t miss the chance to connect with the people shaping AI’s future: register now!
We’d love to hear your thoughts!
👉 Do you agree that adaptation efficiency matters more than raw scale?
👉 How much do benchmarks shape the way you think about AI progress?
👉 Where do you see the most promising path toward AGI coming from?
Your response might be featured in our next issue!