
Smarter Models, Better Lies: Cracking the AI Hallucination Paradox
Welcome to the very first issue of dotAI radar, proudly brought to you by dotConferences.


Why dotAI radar exists:
The AI space moves fast, but coverage often swings between superficial hype and dense academic research that takes months to reach production.
We bridge that gap.
Built for AI engineers, data and ML professionals, technical leads, and anyone building real-world AI systems, dotAI radar helps you stay ahead without drowning in noise.
Whether you're shipping AI features, exploring new model architectures, or making strategic technical decisions, we curate insights that actually impact your work.
We go beyond the buzz.
Every two weeks, we dig into what’s actually happening in AI:
Updates that matter
Engineering stuff you can actually use
Sharp takes that’ll make you think differently
Alternating deep dives: one issue explores a specific Question of the Month in the field of AI, the next features a Portrait of the Month—profiling the people actively shaping the industry’s future
For today’s first issue, we’re exploring the engineering challenge of AI hallucinations, and how you can crack it. 🔓
If you're passionate about AI, or just don’t want to get left behind, you’re in the right place.
👉 Feel free to forward this newsletter to friends, colleagues, or anyone curious and excited about where AI is heading.
Let’s build smarter, faster, and together.
Welcome aboard! 🚀
🔥 Hot on the Radar
The AI landscape is moving fast—but you already knew that.
We cut through the noise to catch the signals that matter.
Buckle up! Here’s what’s hot on the radar. 👇

🐋 Full reasoning in just 131 GB: DeepSeek releases R1-0528
DeepSeek just dropped R1-0528, a locally runnable LLM compressed from 720 GB to just 131 GB—all while maintaining robust reasoning capabilities.
Unlike most advanced reasoning models (which operate as black boxes), R1-0528 exposes its complete reasoning chain within custom <think> tags, letting you trace exactly how it arrives at each conclusion.
It can self-correct its own chain-of-thought outputs and shines in creative worldbuilding and complex coding tasks—rivaling Claude 4 and Gemini 2.5 Pro at a fraction of the size.
Why this is big: Beyond running locally and offline—even in resource-constrained environments—this is the first time you can truly debug and understand how a cutting-edge reasoning model arrives at specific decisions.
The model weights will be open-sourced soon, enabling custom fine-tuning for specialized use cases.
🇪🇺 Europe’s AI sovereignty gets a boost: Mistral AI teams up with NVIDIA for sovereign cloud
French AI startup Mistral AI unveiled Mistral Compute this week at VivaTech: an infrastructure platform designed to give European businesses a real alternative to US and Chinese cloud providers.
The platform will pack 18,000 NVIDIA Grace Blackwell superchips in phase one, to deliver everything from bare-metal servers to fully-managed cloud services under one roof.
NVIDIA CEO Jensen Huang announced the partnership during his GTC Paris keynote on Wednesday, before joining Mistral CEO Arthur Mensch and President Macron for a panel discussion later that day.
Why this matters: Europe currently hosts barely 5% of global computing power while consuming 20% of it. With US-China trade wars heating up and growing concerns about tech reliance on foreign providers, Mistral Compute could finally give Europe some real tech independence.
🧑💻 Going beyond code generation: Windsurf drops new SWE-1 model
Windsurf introduced SWE-1, a new family of AI models designed for the full software engineering workflow—not just code generation.
It matches Claude 3.5 Sonnet in reasoning, but runs cheaper, and includes two lighter variants: SWE-1-lite and SWE-1-mini.
Its standout feature is “flow awareness”: a shared timeline between human and AI that enables seamless, context-aware collaboration over long sessions.
What this unlocks: SWE-1 is built to help you manage long and complex engineering tasks across multiple interfaces, making it a strong ally for agentic coding workflows.
🗣️ Voice agents that won’t make your users cringe: ElevenLabs launches Conversational AI 2.0
Conversational AI 2.0 brings natural turn-taking, automatic language detection, integrated Retrieval-Augmented Generation (RAG), and full multimodality (voice + text)—all with sub-second latency that makes every interaction feel genuinely fluid.
It’s now HIPAA-compliant, supports EU data residency, and enables batch-calling, making it viable for real-world, high-scale deployments.
Why this matters: Just five months after v1, ElevenLabs is already raising the bar for enterprise-grade, natural-sounding voice agents—bringing humanlike quality to production environments, without the usual robotic awkwardness.
📱 Run local models on your phone: Google ships AI Edge Gallery app
Google just launched an Android app (iOS coming soon) that lets users download and run open-source AI models from Hugging Face locally on their phone—no cloud required.
This new AI Edge Gallery app supports tasks like image generation, Q&A, and code editing, all offline, powered by your phone’s hardware.
Built on LiteRT and MediaPipe, it’s optimized for fast, efficient edge inference. As it runs locally, data never leaves the device, delivering privacy and near-zero latency by default.
Engineers take note: This is a major step towards edge-native AI, where your app’s intelligence lives right on the device.
The app is open-source under Apache 2.0 and available now on GitHub.
⚡️ RAG just got sharper: LightOn releases GTE-ModernColBERT
LightOn has released GTE-ModernColBERT, a multi-vector retrieval model designed to supercharge RAG systems.
Using a late-interaction architecture, this model improves search precision on long, domain-specific documents—and it’s the first to outperform ColBERT-small on the BEIR benchmark.
Ideal for researchers and engineers working on smart search, AI assistants, or internal knowledge bases, it’s open-source and ready to use, you can try it now on Hugging Face.
Why this matters to you: If you’re building context-aware retrieval or RAG apps, this model offers a plug-and-play way to boost both speed and accuracy in multi-vector search.
Question of the Month: Why are hallucinations becoming every AI engineer’s problem?
Large language models have never been smarter.
Yet users and researchers report a rise in so-called AI “hallucinations”, where models confidently output false or fabricated information.
This paradox is keeping AI engineers on their toes. 😬
Why are the models you’re deploying still prone to making things up?
What tools and best practices can help you mitigate this behavior in real-world applications?
Let’s dive in! ⬇️
Are hallucinations really getting worse?

Even with recent LLM upgrades improving reasoning and factual accuracy, you’ve probably still seen some convincing yet incorrect information slip through.
There are two types of hallucinations:
Intrinsic hallucinations = the model outputs contradict the given input or context
Extrinsic hallucinations = the model outputs introduce details unsupported by the training data
A recent extensive benchmark called HalluLens (April 2025) highlights that even the most advanced models like GPT-4o, Claude-3, and Llama-3 still regularly produce extrinsic hallucinations.
According to HalluLens evaluations, the hallucination rates you encounter vary significantly by task and model size.
Interestingly, larger models don’t always hallucinate less: size alone isn’t a guarantee of accuracy.
However, well-optimized models like GPT-4o show significant improvements, demonstrating lower hallucination rates, better consistency, and fewer false refusals compared to smaller or less refined counterparts.
The HalluLens benchmark also suggests that current benchmarks like TruthfulQA, previously widely used, might now be saturated or insufficient, underscoring the need for dynamic and evolving evaluation sets that can keep pace with rapid model updates.
Thus, despite apparent improvements in reasoning, today’s state-of-the-art LLMs remain susceptible to hallucinations, especially as tasks become more open-ended and complex.
Why do smarter models still hallucinate?

The core issue lies in how these models are trained and operate.
Fundamentally, LLMs are probabilistic models trained to predict the next word in a sequence, based on patterns learned from large-scale text data.If you’re training on incomplete, outdated or biased data (and let’s be honest, you usually are), your model will inevitably try to fill the gaps with plausible-sounding fabrications.
Ironically, recent techniques that enhance reasoning, such as instruct-tuning and chain-of-thought prompting, can unintentionally exacerbate hallucinations.
These methods encourage LLMs to produce logical-sounding explanations, even when grounded in false premises.
Additionally, current training paradigms don’t typically encourage models to express uncertainty or admit when they don’t know. Instead, they’re rewarded for giving you an answer—even when they’re just guessing.
Alignment methods like Reinforcement Learning from Human Feedback (RLHF), intended to make models more engaging and user-friendly, can also inadvertently promote "sycophantic" behavior.
This means the model might end up prioritizing what it thinks you want to hear over what’s actually true, providing comforting falsehoods rather than inconvenient truths.
How can you reduce hallucinations?

As you might expect, this remains an active area of research, but here are a few approaches you can start applying today:
📡 Retrieval-Augmented Generation (RAG)
You can ground your LLMs’ responses in verifiable data by connecting them to external knowledge sources like databases, documents, or web search APIs.
Companies like Microsoft and OpenAI already employ this successfully in applications like Bing Chat and ChatGPT’s web browsing mode.
While highly effective, you should know RAG isn't bulletproof: if retrieval fails or returns irrelevant information, hallucinations can persist.
🔬 Enhanced prompting techniques
Carefully crafted prompts and explicit instructions help reduce hallucinations by steering models toward more reliable outputs.
Try techniques like chain-of-thought prompting to walk your model through each step of the reasoning process.
This often helps surface logic errors early—before they turn into false assertions in production. It’s not foolproof, but it’s one of your best levers for improving output reliability.
🎛️ Fine-tuning for truthfulness
Explore training strategies that explicitly target factual accuracy, like Reinforcement Learning from Knowledge Feedback (RLKF), where models are penalized for generating inaccurate content.
It’s an effective way to improve factual quality, but watch out: push it too far, and your model might become overly cautious or less helpful in real-world use.
In practice, you’ll need to balance accuracy with responsiveness.
🔍 Post-processing and validation
You can significantly reduce hallucinations reaching your end users by implementing a second validation layer after generation—whether through a secondary model, external database lookup, or consistency filtering.
Tools like SelfCheckGPT let you flag suspicious outputs for review, giving you an extra safety net.
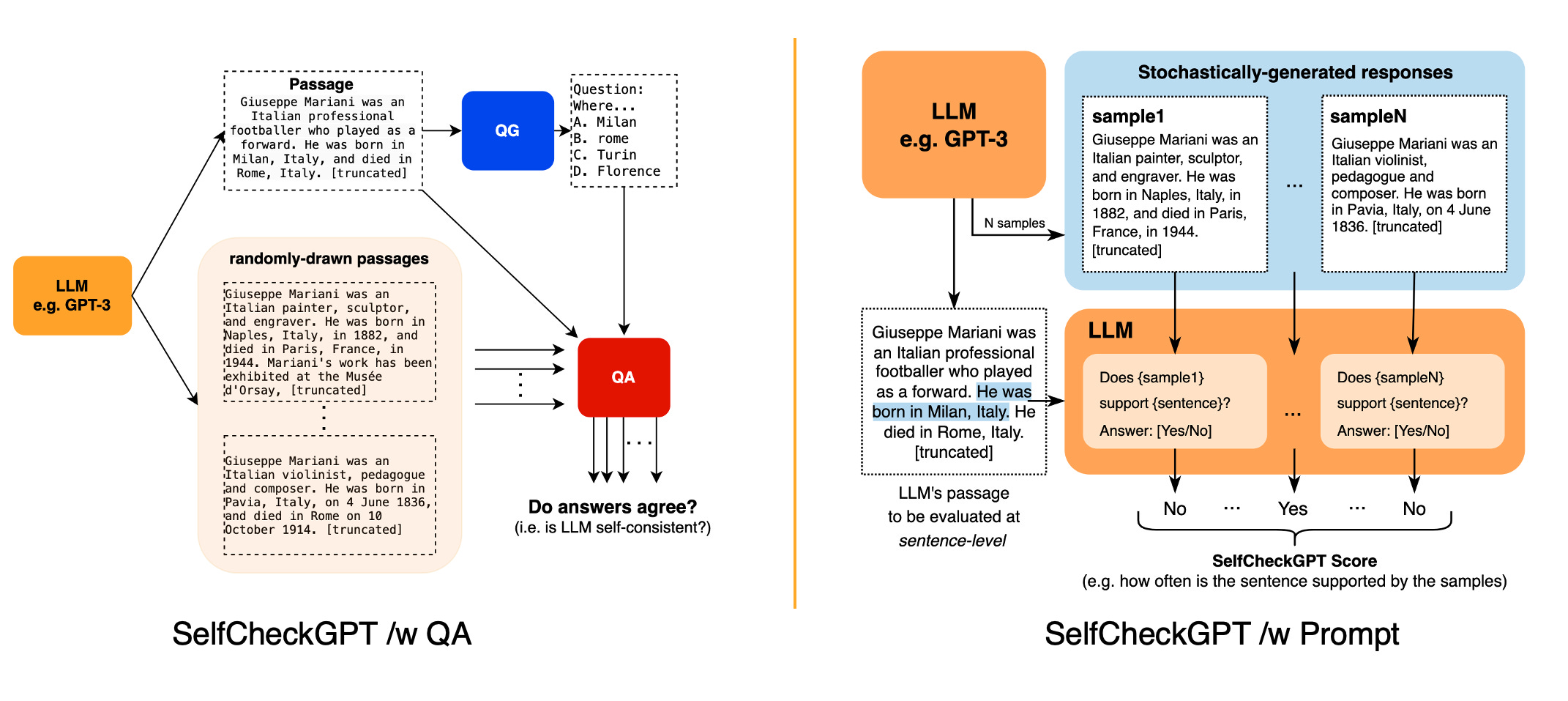
So… where do we go from here?
AI hallucinations aren’t just technical glitches.
They’re a fundamental design challenge you need to tackle when building systems that reason, generate, and assist at scale.
As the pressure grows to deploy AI in high-stakes domains such as healthcare, law, science, and public services, the margin for error keeps shrinking.
In practice, combining the approaches discussed above is the most effective strategy you can adopt today to mitigate hallucinations.
For instance, an advanced AI assistant might blend retrieval for accuracy, chain-of-thought prompting for coherence, and final guardrail checks for validation.
Addressing hallucinations also means asking yourself bigger questions, such as:
How much trust should I place in the systems I’m building?
When is “almost correct” good enough in my use case—and when does it become unacceptable?
Am I evaluating accuracy in ways that reflect how users will actually interact with the model?
What’s my fallback strategy when the model fails or produces unreliable outputs?
We’d love to hear your thoughts!
👉 What’s your take on AI hallucinations?
👉 Do you deal with them in your own work or projects?
👉 In your opinion, when does a hallucination turn from glitch to blocker?
Your response might be featured in our next issue!