
Smaller Models, Bigger Gains? Rethinking AI Strategy
🟡 Welcome back to this new edition of dotAI radar, your shortcut to what matters in AI engineering.


This issue’s Question of the Month goes straight to the heart of one of today’s key technical questions:
Do giant models still make sense for your use cases, or is it time to go specialized?
Cloud LLMs are everywhere, but specialized open-source models are quietly changing the economics and performance of real-world AI.
🫡 We break it down so you can make the right call.
🔥 Hot on the Radar
AI isn’t slowing down and we’re keeping you up to speed.
Here’s what’s hot on the radar this week. 👇
🎯 Big context, small package: Hugging Face releases SmolLM3
Hugging Face has released SmolLM3, a 3-billion-parameter open-source language model that offers strong performance despite its size.
Despite its small size, SmolLM3 supports a massive 128k token context window and offers multilingual capabilities across six languages.
It introduces a dual-mode inference (with or without reasoning traces) and was trained on 11.2 trillion tokens, enabling surprisingly strong performance rivaling larger 4B models.
The key takeaway: SmolLM3 is more than just another small open-source model.
Hugging Face is raising the standard for openess by releasing not only the model itself but also the complete training recipe, architecture choices, data mixtures, and alignment methodology.
This approach makes it easier for developers and researchers to understand how a competitive 3B model is built and to build on top of it, helping democratize long-context multilingual language models.
🧪 Drug discovery, fast-forward: AI model designs antibodies in two weeks
Researchers unveiled Chai-2, a generative AI that drastically accelerates drug discovery.
In lab tests, Chai-2 achieved a 16% hit rate for novel antibodies and found at least one successful binder for 50% of new targets, all in a single round of experiments.
This zero-shot design approach compresses discovery timelines from months or years down to just two weeks, representing a substantial improvement over previous methods.
What makes this significant: This breakthrough suggests AI can engineer therapeutics on-demand, pointing toward a future of faster and more precise drug development.
By compressing discovery cycles from years to just weeks, tools like Chai-2 could help researchers rapidly respond to emerging diseases, accelerate preclinical pipelines, and lower the cost of developing new treatments, helping biotech move faster and adapt more easily.
🤖 Affordable robot meets AI experimentation: Pollen Robotics launches Reachy Mini
Hugging Face and Pollen Robotics just launched Reachy Mini, a small expressive and modular desktop robot built for AI experimentation.

Reachy Mini is fully open-source and programmable in Python (JavaScript and Scratch support coming soon).
It features cameras, microphones, a speaker, a motorized head, and animated antennas, all packed into an affordable kit starting at $299 for the Lite version or $449 for the Wireless version.
For the builders: Reachy Mini makes it easier to test AI models in real-world conditions.
It combines physical interaction capabilities with seamless integration into the Hugging Face ecosystem. The robot comes with preloaded models and behaviors, making it easy to start building and experimenting.
🔮 Predicting human thoughts: Centaur model predicts human decisions with high accuracy
A new AI model called Centaur is bridging psychology and AI by mimicking human decision-making with striking fidelity.
Developed at the Helmholtz Munich research institute, Centaur was trained on 10+ million human decisions from 160 behavioral experiments, enabling it to predict how people will act even in unseen scenarios.
The model not only reproduces choices but also estimates human reaction times, closely matching real cognitive patterns.
Why this matters: Centaur shows that AI can now model not just what we do, but how we think.
This could open new paths for research, training, and even mental health support tools designed to better simulate individual reasoning.
Question of the Month: Should you bet on giant models or go specialized?
Cloud-based AI giants are breaking benchmarks weekly in an all-out AI arms race.
Yet enterprises using specialized open-source models report up to 51% higher positive ROI while achieving comparable or better performance on domain-specific tasks.
This dynamic is forcing enterprises to reconsider their AI strategy.
Why are some specialized models now outperforming giants on your specific use cases?
What development strategies can help you balance performance needs with budget constraints?
Let’s dive in! ⬇️
Do larger models always mean better results?

Even with GPT-4.1, Claude 4 and Gemini 2.5 currently pushing boundaries, you’ve probably noticed your cloud API bills skyrocketing as you scale your AI initiatives.
But the market has evolved beyond “one-size-fits-all”.
While Big Tech continues pushing massive 100B+ parameter models through cloud APIs, a new breed of specialized models—lean at 1-20B parameters—is proving that surgical precision can actually beat brute force for domain-specific tasks.
The recent Stanford AI Index report highlights this shift: specialized models now rival their massive counterparts across critical benchmarks like MMLU, HumanEval, and MATH.
Microsoft's Phi-3-mini (3.8B parameters) is a perfect example, achieving performance benchmarks that not so long ago demanded significantly larger models, all while fitting in just 2.4GB when quantized.
Why do enterprises still default to giant models?

Let’s break it: the convenience factor is undeniable.
Many organizations stick with expensive general-purpose models for tasks that specialized models could handle better and cheaper.
How can we blame them? 🤷♂️
They get instant access to state-of-the-art capabilities without infrastructure headaches, extensive documentation, and regular updates… all through a simple API call.

In addition, few enterprises have the expertise to run or fine-tune their own specialized models, making cloud APIs a convenient shortcut—even when suboptimal.
Yet the economics become critical at enterprise scale.
While cloud giants have become more accessible—GPT-4.1 at $2/$8 per million tokens (input/output), Claude Sonnet 4 at $3/$15—these costs tend to rise quickly with real-world usage.
For context, a mid-sized company running customer service automation, document analysis, and developer assistants can easily consume 50-100M tokens daily.
💡 At GPT-4.1 rates, that's $15,000-30,000 per month—and large enterprises can reach six-figure monthly bills.
But here's what makes specialized models truly compelling: beyond eliminating these recurring costs, they unlock capabilities that cloud models simply can't match.
Edge deployment delivers sub-10ms latency (vs 100-500ms for cloud), complete data sovereignty for regulated industries, and unlimited local inference after one-time setup.
👉 This means you can now run AI models on edge devices that previously required expensive cloud infrastructure, changing both the economics and capabilities of enterprise AI.
How can you implement specialized models effectively?

Now here's where your technical team can shine. ✨
🔧 Parameter-Efficient Fine-Tuning (PEFT)
Recent research shows you can achieve comparable performance to full fine-tuning while training less than 1% of parameters.
Think of it like teaching a polymath doctor to become a specialist: instead of retraining their entire medical knowledge, you're adding a specialized lens through which they view specific problems.
LoRA (Low-Rank Adaptation) works by injecting trainable low-rank matrices into the model’s layers, leaving the rest of the network frozen.
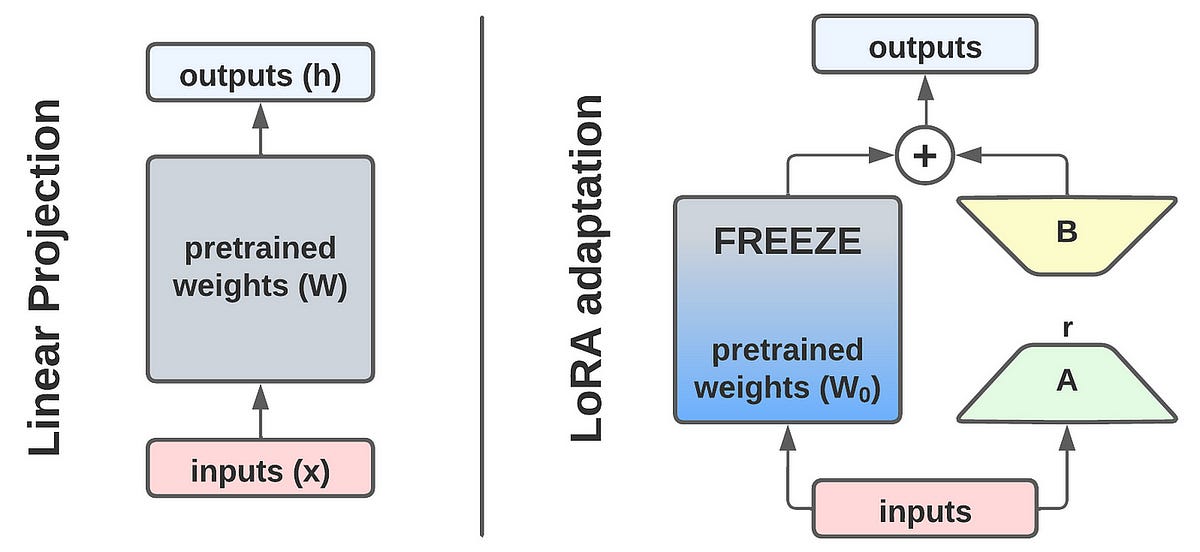
As a result, LoRA-based tuning achieves performance close to full-parameter fine-tuning, with only a couple percent drop in accuracy for massive efficiency gains—for instance on this Anyscale's Llama-2 analysis which resulted in 95% vs 97% on a 13B model.
In practice, LoRA also enables fine-tuning on smaller hardware, reducing GPU memory requirements—and therefore costs.
📦 Quantization without quality loss
Modern quantization techniques let you compress models significantly with minimal to zero performance loss.
One popular approach, Q4_K_M quantization, cuts model size by approximately 75% while maintaining near-full accuracy.
In other words, you get around 95% of the original model’s capability in a file a quarter the size.
But here’s a plot twist: quantization isn’t always a downgrade!
A recent case study on the Yi-34B model, used for code generation, found that a 4-bit Q4_K_M quantized version actually outperformed the 16-bit model on complex prompts (even those requiring chain-of-thought reasoning).
Don’t fear going low-bit! Lower precision can sometimes reduce overfitting or noise, leading to better results in specific scenarios.
With advanced techniques (GPTQ, AWQ, etc.) and a bit of validation, you can compress your models to run on modest hardware, often without losing accuracy.
🍵 Model distillation: compressing giants without sacrificing performance
Training giant models is costly, but what if you could distill their knowledge into smaller, faster, and cheaper models, without losing performance?
Unlike quantization, distillation requires a dedicated training process to transfer knowledge from a large “teacher” model to a smaller “student” model.
Instead of training the smaller model from scratch, it learns by mimicking the nuanced predictions (called "soft targets") from its larger counterpart.
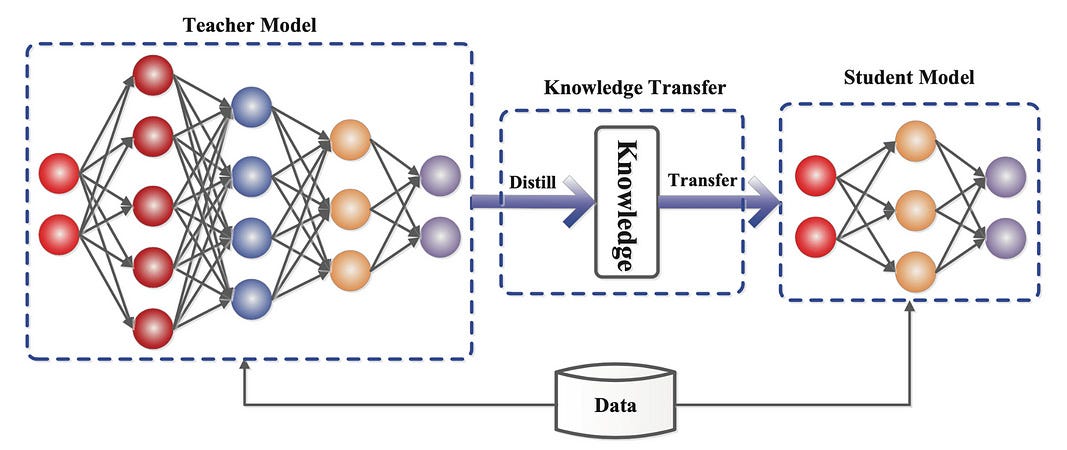
In practice, this approach has delivered impressive results. DistilBERT, Hugging Face’s distilled version of Google’s BERT, retains about 97% of BERT's accuracy while running 60% faster and being 40% smaller, making it ideal for edge devices or resource-limited environments.
However, distillation isn’t magic: the smaller the model, the harder it is to replicate complex reasoning capabilities.
The quality of the "teacher" model also matters immensely: a flawed teacher leads to flawed students. Additionally, while distillation reduces operational costs, the initial training phase still requires substantial computing resources.
Yet when combined intelligently with techniques like quantization and fine-tuning, distillation enables businesses to deploy powerful AI solutions directly on edge devices.
🚀 Edge deployment goes mainstream
Not long ago, the idea of running GPT-level models on a laptop or even a phone seemed like a crazy wish.
By combining those lean 4-bit models with optimized runtimes, you can deploy AI at the edge, and reap massive gains in speed and privacy.
💡 We’re talking inference latencies of 10–50 ms on local devices versus 100–500 ms typical for cloud APIs. For any real-time application, that difference is significant.
Moreover, running on the edge means your data never leaves your environment. This is huge for regulated industries like healthcare, finance, or defense that demand strict data sovereignty.
Technically, the barrier to entry has lowered considerably.
A quantized 7B–13B parameter model (with 4-bit weights) needs on the order of 4–8 GB of RAM, putting it within reach of consumer GPUs.
In fact, specialized models are already running on high-end smartphones using libraries like ONNX Runtime and CoreML.
These edge-optimized runtimes can deliver additional performance (often 20 up to 30% faster inference) by taking advantage of device-specific accelerators.
The end result: sub-100 ms response times, no bandwidth costs, and full control of your models.
🔄 Hybrid architectures for best of both worlds
How about winning with AI without picking sides?
Smart teams are blending local and cloud models into hybrid systems that optimize cost, speed, and quality simultaneously.
The strategy is straightforward: use intelligent routing to match each task to the right model.
👉 If a user query or transaction looks routine, a lightweight local model handles it instantly. If something requires heavy reasoning or broad knowledge, it’s routed up to a cloud powerhouse. This way, you reserve the expensive cloud calls only for the hard cases.
Hybrid approaches also allow you to address other constraints: for example, keep all personally identifiable data local (to satisfy compliance), while still using a cloud model for non-sensitive tasks like general research.
Or use edge models to handle surges in demand, avoiding slowdowns when your cloud API rate-limits or goes down.
The key is orchestration. Companies are implementing smart gateways (such as OpenRouter) that analyze each request and dynamically decide “local vs cloud” based on rules—or even another AI model.
This approach delivers cost reduction while maintaining flexibility.
What’s the right trade-off?
You’re not choosing between David and Goliath anymore.
It's about building intelligent orchestration that maximizes value from every compute dollar.
As model costs drop significantly and specialized capabilities rise, the winners will be organizations that design flexible, hybrid systems combining the best of both worlds.
Also, not every use case demands specialization. ⬇️
Use cloud giants when you need:
Broad general knowledge across domains
Rapid prototyping and experimentation
Creative tasks requiring extensive training data
Low-volume, high-complexity queries
Minimal infrastructure investment
Consider deploying specialized models when you have:
High-volume, domain-specific tasks
Predictable query patterns
Latency-sensitive applications
Data privacy requirements
Budget constraints at scale
We’d love to hear your thoughts!
👉 Have you tried splitting workloads between cloud APIs and specialized models?
👉 How do you evaluate if a specialized model is worth the deployment effort?
👉 How are you managing the complexity of multi-model architectures?
Your response might be featured in our next issue!